So while surfing X I stubbled on a Reddit post: Wow… we’ve been burning money for 6 months
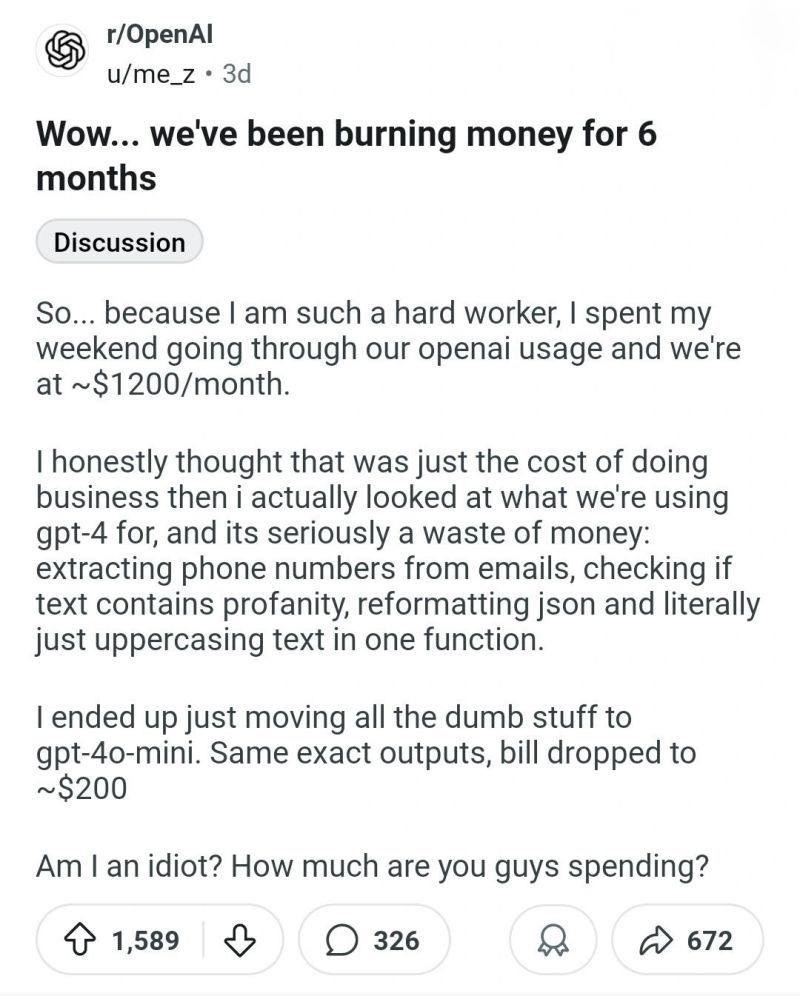
What you’re seeing here is a perfect example of how technology adoption always overshoots before it stabilizes.
A team ends up spending 1200 USD a month to get a neural net to… uppercase text.
That’s the equivalent of hiring an aerospace engineer to inflate your kid’s bicycle tires.
Why?
Because when shiny new tech shows up, companies grab it wholesale. They don’t stop to ask: What do we actually need this for?
The result is waste, burning money on GPT-4 to do what a Python script from 10 years ago, or one of those 123456 npm packages, could handle in milliseconds.
The reality is that advanced AI – sorry, LLM – has real value when context matters, like detecting nuance, intent, or gray-area profanity.
But when you ask it to strip phone numbers out of emails, you’re turning a Bentley into a pizza delivery scooter.
Yes, it’ll work.
But you’ll go broke using it.
What comes next?
SMEs will rediscover interns and open-source libraries. They’ll also move to lighter local models like LLaMA, combined with some duct tape and bpa automation tools like n8n.
Lower cost, more control.
Of course, that comes with its own SysOps and server tax – because infrastructure never runs itself.
But how much? Well… for most of my clients, less than 200 USD per month!
The bigger picture?
This is the messy middle of AI adoption.
The hype says everything must be AI.
The reality is most things shouldn’t be.
And until businesses learn to draw that line, they’ll keep burning money on Bentleys that deliver pizzas.
Do you see the parallels to every other tech bubble?
Or are we really just living through another Terminator movie, except this time the punchline is that the robots are wasting our money, not nuking us?
Why New Tech Always Starts Wasteful
The post-mortem on any technological breakthrough almost always reveals a period of glorious, reckless waste. This isn’t a bug; it’s a feature of the innovation cycle itself. From the dot-com bubble to the present-day AI frenzy, new tech adoption follows a predictable pattern: a cycle of hype, followed by widespread overuse, and finally, a necessary correction that brings sanity – and real value – to the market.
Phase 1: The Hype Cycle
Every truly disruptive technology arrives with a bang, promising to solve every problem and rewrite every industry. The initial buzz is intoxicating. VCs pour money into startups, media headlines declare a new era, and businesses, terrified of being left behind, rush to embrace the shiny new thing. This is the stage where the technology’s potential is at its peak, and its practical limitations are conveniently ignored. The conversation isn’t about if a company should adopt it, but how fast.
Phase 2: Overuse and Reckless Spending
In the grip of the hype, organizations begin to apply the new technology indiscriminately. They don’t just solve problems; they invent problems for the new solution to fix. This is the “Bentley to deliver pizzas” phase. A simple task that could be handled by a cheap, existing tool is suddenly re-engineered with the latest, most expensive tech.
We saw this exact pattern play out with cloud computing. When AWS and others first emerged, the promise of “pay-as-you-go” elasticity was revolutionary. But what followed was an era of “cloud sprawl.” Companies moved every single workload to the cloud, often without optimizing them. They ran bloated, inefficient servers 24/7 for a few hours of peak use, racking up massive bills. Many used high-end, expensive cloud databases for simple tasks that could have run on a local server for a fraction of the cost. The mindset was “cloud first,” without ever asking, “Is the cloud best for this specific purpose?” The result was billions of dollars in wasted compute power.
Blockchain is another perfect example. After the Bitcoin boom, every company wanted its own blockchain. There was a flurry of “blockchain for supply chain,” “blockchain for voting,” and even “blockchain for… tracking coffee beans.” Many of these projects were little more than glorified, distributed databases that offered none of the key benefits of a true decentralized ledger. The technology was a solution in search of a problem, and countless startups burned through capital before the market corrected, leaving a much smaller, more focused group of practical use cases.
Even more recently, Kubernetes and container orchestration fell into this trap. Originally designed to manage complex, large-scale microservices, it became the default choice for deploying simple applications. Engineers would spend months building a full-blown Kubernetes cluster to host a simple web app that could have run happily on a single virtual machine. This “over-engineering” led to significant increases in complexity, hiring costs, and operational overhead – all for a problem that didn’t exist.
Phase 3: The Correction
This phase begins when the bills come due and the promised ROI fails to materialize. CFOs start asking tough questions. Engineers and product managers, tired of wrestling with over-engineered solutions, begin to look for simpler, more cost-effective alternatives.
The market self-corrects. Companies that were once all-in on a single technology start to diversify their toolkits. They “rediscover” older, proven solutions. With cloud computing, this led to the rise of FinOps (financial operations for the cloud), where teams are now specifically dedicated to optimizing cloud spending. With blockchain, the hype died down, leaving a more realistic understanding of where the technology truly adds value (e.g., decentralized finance, asset tokenization). With Kubernetes, the industry has seen a push toward simpler solutions like serverless platforms and managed services that abstract away the complexity.
The Bigger Picture
This is the messy, middle part of any technological revolution. The initial overshooting isn’t a sign of failure; it’s a necessary step. It’s how the market learns what a technology is really for and what its true value is. The initial waste is the price of the collective learning process. It’s an expensive lesson, but it’s one that ultimately leads to more mature, efficient, and thoughtful adoption.
The current AI hype cycle is no different. We are in the thick of the overuse phase, where companies are turning Bentleys into pizza delivery scooters. But the correction is already beginning. And when it’s over, we’ll be left with a much clearer picture of what AI can, and should, be used for – a tool for genuine innovation, not just a wasteful fad.
This kind of overkill mirrors what we’ve already seen with AI’s limits – for example in detecting malicious code with generative models.
When a Neural Net Uppercases Text
At some point in the near future, we will look back at this moment and cringe with a mix of amusement and horror. We will tell stories of the early AI boom, much like how a previous generation talks about the “paperless office” or the “next big thing” that wasn’t. The anecdote that will best capture this absurdity is the team that spent twelve hundred dollars a month on a neural network to uppercase text.
This is the digital equivalent of hiring an aerospace engineer to inflate your kid’s bicycle tires.
Think about it. An aerospace engineer is a specialist in a domain of immense complexity – designing spacecraft, optimizing jet propulsion, and calculating orbital mechanics. Their skills are honed for problems where a single decimal point error could be catastrophic. To task them with something as trivial as pumping a bicycle tire is not just inefficient; it’s a profound misuse of expertise. A hand pump, a five-dollar tool, accomplishes the same job in less than a minute. The aerospace engineer might get the job done, but it would be an expensive, overcomplicated, and utterly wasteful exercise.
In the world of AI, this kind of technological overkill is happening everywhere.
Using a Full-Stack Web App for a Static Page: A small business wants a simple website with a homepage, an “About Us” section, and a contact form. A developer, caught up in the modern tech stack, builds a complex, full-stack application using a JavaScript framework, a cloud-based serverless backend, and an enterprise-grade database. The result is a site that requires constant maintenance, carries a monthly hosting fee, and is a nightmare to update. What was needed? A simple HTML file. Or a basic template on a free website builder. The difference in cost and effort is staggering.
The Big Data Solution for a Simple Report: A manager needs a report showing weekly sales figures, a task that a simple Excel spreadsheet could handle with a pivot table. Instead, a data team decides to build a full-blown “Big Data” pipeline. Data is extracted, transformed, and loaded into a data lake, then processed by a series of complex data models, and finally visualized in a BI (Business Intelligence) tool. While such a pipeline is essential for massive datasets, applying it to a few thousand rows of sales data is an act of pure professional pride – not practicality. The operational overhead and licensing fees dwarf the value of the insights gained.
The “Blockchain for Everything” Fallacy: In the mid-2010s, after the rise of Bitcoin, countless startups emerged with “blockchain solutions” for mundane problems. There were proposals for a blockchain to track organic food, a blockchain for managing digital rights, and a blockchain to verify product authenticity. The vast majority of these use cases didn’t require a decentralized, immutable ledger. A simple, centralized database would have been cheaper, faster, and more efficient. The technology was applied not because it was the best fit, but because “blockchain” was the trendy keyword that attracted investment.
This over-engineering mindset is born from a mix of genuine excitement and a fear of being left behind. Companies hear about a new technology and believe it’s a silver bullet for every problem. The result is a professional class of “aerospace engineers” who, with the best of intentions, use their most advanced tools to perform the most basic tasks.
The good news is that this phase is always temporary. The market eventually corrects, reality sets in, and organizations learn to apply technology with a dose of pragmatism. The true value of AI, like any powerful technology, isn’t in its ubiquity, but in its specific and targeted application – in the complex, gray-area problems that simple tools can’t touch. Until we learn that lesson, we’ll keep burning money on Bentleys that deliver pizzas.
Responsible use matters – just look at Singapore’s distinctive approach to Responsible AI
The Right Tool for the Right Job
In technology, as in carpentry, the principle of proportionality is paramount. It means that the complexity, cost, and effort of the solution must be commensurate with the scale and nature of the problem. Choosing a solution that is too powerful or too complex for a simple task doesn’t just waste money; it introduces unnecessary overhead, fragility, and maintenance burdens. This is the difference between a simple, lightweight tool and a heavy, multi-purpose machine.
The recent AI boom has blurred this line, leading many to reach for the most powerful tool available, regardless of the job.
Lightweight vs. Heavyweight Solutions
Think of a lightweight solution like a simple hand tool. It’s purpose-built, efficient, and cheap. A Python script or an npm package is the equivalent of a power drill or a screwdriver. It’s designed to perform a specific function – like stripping phone numbers from emails or uppercasing text – and it does so with incredible speed and minimal overhead. These tools are fast, reliable, and require almost no ongoing cost once deployed. They’re part of a mature ecosystem of open-source libraries that have been refined over a decade or more to handle common tasks with rock-solid efficiency.
A heavyweight solution, like GPT-4, is an industrial-scale manufacturing plant. It’s a massive, multi-purpose system built to handle immense complexity and solve problems that require a vast understanding of nuance and context. Its strength lies in its ability to handle “gray area” tasks, like summarizing a complex legal document, detecting subtle sentiment in customer feedback, or generating creative, original content. Using it for a simple, deterministic task is a spectacular waste of resources. Not only do you pay a premium for every API call, but you’re also using a powerful, general-purpose engine to do a job that a simple, purpose-built script could handle in a few lines of code.
The Principle of Proportionality in Action
The most successful tech adoption is guided by proportionality, not hype. Here’s how it plays out:
Problem: You need to extract specific, structured data from a large number of documents.
Proportional Solution: Use a lightweight, open-source library like Tesseract OCR for text extraction, combined with a Python regex script to pull out the exact information you need. This is a targeted, efficient, and cost-effective solution.
Disproportionate Solution: Feed all the documents into a high-cost LLM API, asking it to “find the data.” While it will work, it’s expensive, much slower, and can be less reliable for structured data compared to a fine-tuned script.
Problem: You need a simple automation to move a file from one folder to another when a new one arrives.
Proportional Solution: Use an off-the-shelf, no-code/low-code automation tool like n8n or Zapier. These tools are built for this exact purpose, offering visual workflows and direct integrations that are cheap and easy to set up.
Disproportionate Solution: Build a complex, bespoke microservice that uses a containerized, cloud-hosted function and a message queue system. This “solution” introduces significant operational overhead and development costs for a trivial problem.
Ultimately, the goal of technology is to solve problems, not to consume the latest fads. The correction in the AI market will be the return of proportionality – a rediscovery that for most problems, the simplest, cheapest, and most targeted tool is still the best one. It’s a return to first principles, where engineering is about solving a problem elegantly and efficiently, not just using the most powerful toy in the box.
For many SMEs, the real wins come from smart automation – as shown in Business Automation 101
When LLMs Shine: The Domain of Nuance
Large language models (LLMs) are best used for tasks that require nuanced understanding, contextual reasoning, and a human-like grasp of language. These are problems where a simple, deterministic rule can’t account for the subtle variations, ambiguous phrasing, or subjective judgment inherent in human communication.
That’s where cutting-edge models like Google’s Gemini or efficient training tricks for large models
LLMs excel at tasks that fall into a gray area, where the correct answer isn’t a simple binary choice but requires interpretation. Their power comes from their training on massive, diverse datasets, which allows them to understand the implicit patterns and context behind human language.
Creative Content Generation: Whether it’s drafting a blog post, writing marketing copy, or brainstorming product names, LLMs can produce original, stylistically consistent text. A rules-based system could never generate a poem or write a news article because these tasks require a model of creativity and a vast, interconnected web of semantic understanding.
Customer Support and Interaction: LLMs are increasingly used in advanced chatbots that can understand user intent, even when the query is poorly worded or contains slang. Instead of just searching a knowledge base for keywords, an LLM-powered assistant can infer the user’s frustration, recognize a request for a refund hidden within a rant, and provide a helpful, empathetic response. This requires an understanding of tone and sentiment that is beyond the scope of a simple “if/then” rule.
Complex Summarization and Analysis: Summarizing a 50-page legal document or a long-form research paper isn’t just about extracting key sentences. It’s about synthesizing information, identifying the core arguments, and presenting them in a new, concise format. An LLM can perform this kind of contextual distillation, whereas a rules-based program would likely just pull the first sentence of each paragraph, creating a nonsensical result.
Knowledge-Based Q&A: When you ask a question like, “What were the main reasons for the fall of the Roman Empire?” you’re not looking for a single data point. You’re asking for a synthesized answer based on a vast body of historical knowledge. An LLM can access and weave together information from its training data to construct a coherent, comprehensive response that would be impossible for a simple lookup table or a rules-based system.
Sentiment Analysis and Intent Detection: It’s easy to write a rule that flags the word “terrible” as negative. But what about the sentence, “The customer service was terribly good!”? An LLM can understand the ironic or sarcastic intent, whereas a rules-based system would incorrectly categorize it as a negative review. This is where LLMs excel – in the subtle, context-dependent judgments that are second nature to humans but maddeningly complex for a machine.
The Best Tool Isn’t Always the Biggest
In contrast, the following tasks are better handled by rules-based or deterministic approaches. These are problems where the correct solution is unambiguous and predictable, with no room for interpretation.
Structured Data Extraction: If you need to pull phone numbers, email addresses, or social security numbers from a document, a rules-based regex (regular expression) script is the best choice. It’s faster, cheaper, and perfectly accurate because the data has a fixed, predictable format. An LLM might “hallucinate” a number or miss a non-standard entry, whereas a well-written regex will be 100% reliable.
Categorization and Classification: For clear-cut categories – such as sorting customer support tickets by department (e.g., “Billing,” “Technical Support,” “Refunds”) or flagging spam emails – a rules-based approach is ideal. It provides consistent, predictable results every time, which is essential for automation and workflow management.
System Automation: When a specific event triggers a specific action (e.g., “if a user signs up, send a welcome email”), a rules-based system is a no-brainer. These workflows are deterministic by design and don’t require the flexibility or interpretive power of an LLM.
Data Validation: Checking if a credit card number is valid or if a password meets a specific length and character requirement is a task that must have a black-and-white outcome. A rules-based system can perform these checks instantly and reliably.
Ultimately, the power of an LLM is not in its ability to do everything, but in its unique capacity to handle the messiness of human language. The path to efficient tech adoption lies in understanding this distinction and applying the right tool for the right job, leaving the Bentleys in the garage for the tasks that truly demand their power.
Stop Burning Money on the Wrong Tools
The current AI boom is a classic example of technological overshooting – a period of reckless spending where powerful new tech is applied to problems it was never meant to solve. We’re seeing companies spend fortunes on large language models (LLMs) to perform simple, deterministic tasks that a cheap, rules-based script could handle in milliseconds. This is the equivalent of using a Bentley to deliver a pizza – it works, but it’s a monumental waste of resources.
The key to navigating this messy middle of AI adoption is to return to the principle of proportionality: use the right tool for the right job.
For simple, predictable tasks like uppercasing text or extracting phone numbers, lean on lightweight, reliable solutions like Python scripts and open-source packages. They are faster, cheaper, and more accurate.
For tasks requiring nuance and judgment, like generating creative content or understanding complex customer sentiment, LLMs are the perfect tool. They excel in the gray areas where a rigid set of rules falls apart.
This isn’t about rejecting AI; it’s about applying it thoughtfully and efficiently. The goal is to maximize innovation without bankrupting your business. The correction is coming, and smart organizations will be the ones who learn to draw the line between a powerful solution and an expensive, unnecessary one.